

Le NLP est partout : dans nos smartphones, nos moteurs de recherche, nos traducteurs, nos services clients automatisés. Mais que se cache-t-il vraiment derrière cet acronyme ?
Définition du traitement du langage naturel
Le NLP, ou Natural Language Processing, désigne l’ensemble des techniques informatiques qui permettent à une machine de comprendre, d’interpréter et de générer du langage humain, écrit ou parlé.
Le langage humain n’a rien à voir avec un langage de programmation. Il est riche, contextuel, souvent imprécis. Une même phrase peut avoir plusieurs sens selon le contexte, le ton ou les sous-entendus.
L’objectif du NLP ? Combler ce fossé entre la façon dont nous communiquons naturellement et la façon dont les ordinateurs traitent l’information, sous forme de données structurées.
Cette discipline se situe à la croisée de plusieurs domaines :
- La linguistique informatique
- L’intelligence artificielle
- Les statistiques
- Le deep learning (apprentissage profond)
Le NLP constitue aujourd’hui l’un des piliers majeurs de l’IA moderne, au même titre que la vision par ordinateur.
Comment fonctionne le NLP ?
Pour traiter du texte ou de la parole, une machine doit d’abord transformer ce langage en une représentation qu’elle peut manipuler mathématiquement. Ce processus combine règles linguistiques et modèles statistiques ou neuronaux, appris à partir de grandes quantités de données.
Le rôle du machine learning
Historiquement, les premiers systèmes de NLP reposaient sur des règles écrites à la main par des linguistes : grammaires, dictionnaires, arbres syntaxiques. Précise dans les cas simples, cette approche atteignait vite ses limites face à la diversité du langage réel.
L’arrivée du machine learning a tout changé. Concrètement, plutôt que de coder des règles explicites, on entraîne désormais des modèles sur de vastes corpus de textes, en leur apprenant à repérer des régularités statistiques dans l’usage de la langue.
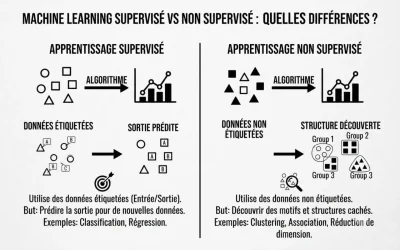
À lire aussi : comment différencier les modèles de machine learning supervisés et non supervisés ?
Cela permet aux modèles de généraliser à des phrases jamais vues auparavant. Résultat : des systèmes bien plus robustes et adaptables que les approches à base de règles.
Modèles de langage et réseaux de neurones
Les avancées les plus marquantes viennent des réseaux de neurones, et en particulier de l’architecture Transformer, apparue en 2017. Ces réseaux permettent de représenter le sens d’un mot en fonction de son contexte, et non plus de façon isolée.
C’est cette architecture qui est à l’origine des grands modèles de langage (LLM, pour Large Language Models) que l’on connaît aujourd’hui. Entraînés sur des quantités massives de textes, ils apprennent des représentations vectorielles du langage, les fameux « embeddings », qui capturent des relations sémantiques subtiles entre mots, phrases et concepts abstraits.
Les principales étapes du traitement automatique du langage
Comment un texte passe-t-il de simple suite de caractères à contenu compris par une machine ? Le traitement suit généralement plusieurs étapes successives, chacune ajoutant un niveau de compréhension.
| Étape | Ce qu’elle fait |
|---|---|
| Analyse morphologique | Découpe le texte en mots, identifie racines, genre, nombre, temps |
| Analyse syntaxique | Étudie la structure grammaticale des phrases |
| Reconnaissance d’entités nommées | Repère noms de personnes, lieux, dates, montants |
| Analyse sémantique | Saisit le sens global et le contexte |
Analyse syntaxique et morphologique
La première étape consiste à décomposer le texte en unités élémentaires. C’est la tokenisation : elle découpe le texte en mots ou en sous-unités.
Viennent ensuite les analyses morphologiques, qui identifient la racine des mots, leur genre, leur nombre ou leur temps grammatical. On parle ici de lemmatisation et de stemming.
L’analyse syntaxique, elle, étudie la structure grammaticale des phrases : sujet, verbe, compléments, arbres syntaxiques. Cette étape permet à la machine de comprendre comment les mots s’articulent pour former du sens.
Reconnaissance des entités nommées
Une fois la structure grammaticale établie, les systèmes de NLP cherchent à repérer les éléments d’information clés. La reconnaissance d’entités nommées (NER, Named Entity Recognition) identifie et classe automatiquement les noms de personnes, d’organisations, de lieux, de dates ou de montants.
Cela vous permet, par exemple, d’extraire automatiquement des données précises dans des documents juridiques, financiers ou administratifs volumineux, sans avoir à les relire un par un.
Analyse sémantique et compréhension du contexte
L’analyse sémantique va plus loin : elle cherche à saisir le sens global d’un texte, au-delà de sa simple structure grammaticale. Il s’agit de comprendre les relations entre concepts, de désambiguïser les mots à plusieurs sens et de tenir compte du contexte.
C’est précisément là que les modèles de langage modernes excellent. Ils sont capables de prendre en compte l’ensemble d’un document, voire une conversation entière, pour affiner leur interprétation d’un mot ou d’une expression.
Applications concrètes du NLP au quotidien
Le NLP n’a rien d’une technologie abstraite réservée aux laboratoires de recherche. Elle est intégrée dans de nombreux outils que nous utilisons chaque jour, souvent sans même en avoir conscience.
Chatbots et assistants conversationnels
Les chatbots et assistants vocaux reposent entièrement sur le NLP pour comprendre les requêtes des utilisateurs et y répondre de manière pertinente. Ils combinent compréhension du langage naturel et génération de réponses cohérentes.
Cela vous permet d’obtenir une réponse à une question posée avec vos propres mots, sans avoir à formuler une requête « à la machine ».
Traduction automatique et correction linguistique
La traduction automatique s’appuie sur des modèles de NLP entraînés sur d’énormes corpus multilingues. De la même façon, les correcteurs orthographiques et grammaticaux utilisent des techniques de NLP pour détecter les erreurs, mais aussi pour suggérer des reformulations stylistiques.

En pratique, ces outils analysent votre phrase dans son ensemble, et pas seulement mot par mot, pour proposer une correction pertinente.
Analyse de sentiment et classification de documents
De nombreuses entreprises utilisent le NLP pour analyser automatiquement les avis clients, les commentaires sur les réseaux sociaux ou les retours d’enquêtes de satisfaction.
L’analyse de sentiment détermine si un texte exprime une opinion positive, négative ou neutre. Cela vous permet d’obtenir une vision synthétique de la perception d’une marque ou d’un produit, sans avoir à lire chaque commentaire individuellement.
La classification automatique de documents, quant à elle, permet de :
- Trier et catégoriser de grands volumes de textes
- Organiser des e-mails automatiquement
- Détecter les spams
- Classer des articles de presse par thématique
Les enjeux et limites actuelles du NLP
Le NLP a fait des progrès impressionnants. Mais peut-on vraiment dire qu’une machine « comprend » le langage comme un humain ? Pas tout à fait, et plusieurs défis le rappellent.
La gestion des nuances et du langage familier
L’ironie, l’humour, les sous-entendus ou les expressions familières restent des obstacles majeurs pour les systèmes de NLP. Ces formes de langage reposent souvent sur un contexte culturel ou situationnel difficile à modéliser.
ETL expliqué : comment il transforme et centralise vos flux de données ?
Une phrase peut ainsi avoir un sens totalement opposé à son interprétation littérale, selon le ton ou l’intention du locuteur.
La qualité et le volume des données d’entraînement
La performance d’un modèle de NLP dépend directement de la qualité et de la diversité des données sur lesquelles il a été entraîné. Un corpus mal équilibré, contenant des erreurs, des biais ou une représentation insuffisante de certaines langues ou registres de langage, peut entraîner des performances dégradées.
Concrètement, cela signifie que certaines langues, certains dialectes ou certains publics sont moins bien servis par les outils actuels.
Considérations éthiques et biais algorithmiques
Enfin, le NLP soulève des questions éthiques importantes. Entraînés sur des textes produits par des humains, les modèles de langage peuvent reproduire, voire amplifier, des biais présents dans les données : stéréotypes de genre, biais culturels ou discriminations diverses.
La transparence, l’explicabilité des décisions prises par ces systèmes et le respect de la vie privée des utilisateurs constituent également un enjeu central. Ce point devient d’autant plus sensible que le NLP se déploie dans des domaines comme le recrutement, la santé ou la justice.

0 commentaires